Publications
For a complete and up-to-date publication list, check my Google Scholar profile
2024
- NeurIPS
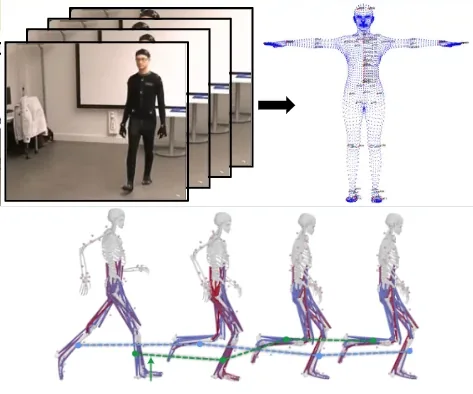 Muscles in time: Learning to understand human motion in-depth by simulating muscle activationsDavid Schneider, Simon Reiß, Marco Kugler, Alexander Jaus, Kunyu Peng, Susanne Sutschet, Muhammad Saquib Sarfraz, Sven Matthiesen, and Rainer StiefelhagenAdvances in Neural Information Processing Systems, 2024
Muscles in time: Learning to understand human motion in-depth by simulating muscle activationsDavid Schneider, Simon Reiß, Marco Kugler, Alexander Jaus, Kunyu Peng, Susanne Sutschet, Muhammad Saquib Sarfraz, Sven Matthiesen, and Rainer StiefelhagenAdvances in Neural Information Processing Systems, 2024Exploring the intricate dynamics between muscular and skeletal structures is pivotal for understanding human motion. This domain presents substantial challenges, primarily attributed to the intensive resources required for acquiring ground truth muscle activation data, resulting in a scarcity of datasets.In this work, we address this issue by establishing Muscles in Time (MinT), a large-scale synthetic muscle activation dataset.For the creation of MinT, we enriched existing motion capture datasets by incorporating muscle activation simulations derived from biomechanical human body models using the OpenSim platform, a common framework used in biomechanics and human motion research.Starting from simple pose sequences, our pipeline enables us to extract detailed information about the timing of muscle activations within the human musculoskeletal system.Muscles in Time contains over nine hours of simulation data covering 227 subjects and 402 simulated muscle strands. We demonstrate the utility of this dataset by presenting results on neural network-based muscle activation estimation from human pose sequences with two different sequence-to-sequence architectures.
@article{schneider2024mint, title = {Muscles in time: Learning to understand human motion in-depth by simulating muscle activations}, author = {Schneider, David and Reiß, Simon and Kugler, Marco and Jaus, Alexander and Peng, Kunyu and Sutschet, Susanne and Sarfraz, Muhammad Saquib and Matthiesen, Sven and Stiefelhagen, Rainer}, journal = {Advances in Neural Information Processing Systems}, volume = {37}, pages = {67251--67281}, year = {2024}, dimensions = {true}, } - ECCVW
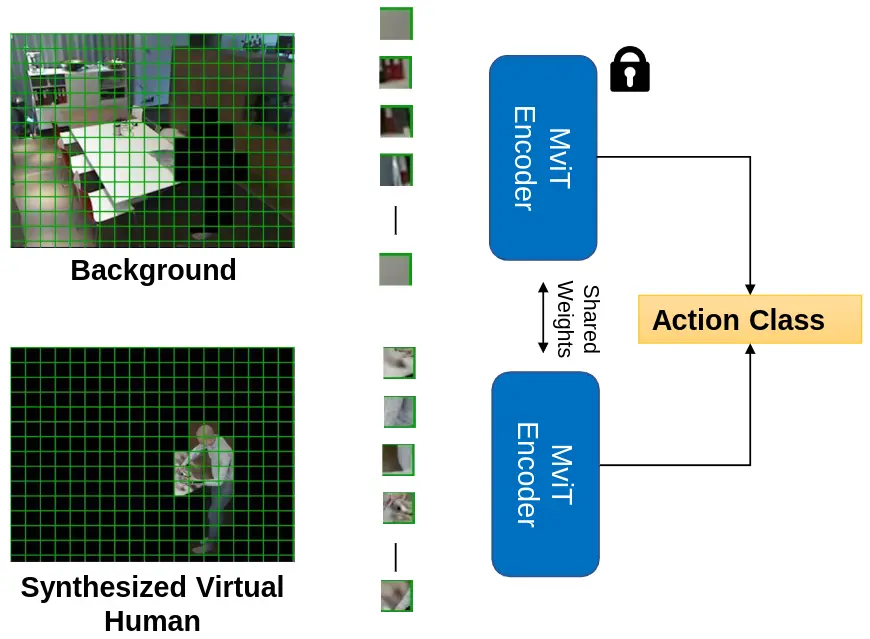 Masked Differential PrivacyDavid Schneider, Sina Sajadmanesh, Vikash Sehwag, Saquib Sarfraz, Rainer Stiefelhagen, Lingjuan Lyu, and Vivek SharmaIn Presented at the 2nd International Workshop on Privacy-Preserving Computer Vision, ECCV, 2024
Masked Differential PrivacyDavid Schneider, Sina Sajadmanesh, Vikash Sehwag, Saquib Sarfraz, Rainer Stiefelhagen, Lingjuan Lyu, and Vivek SharmaIn Presented at the 2nd International Workshop on Privacy-Preserving Computer Vision, ECCV, 2024Privacy-preserving computer vision is an important emerging problem in machine learning and artificial intelligence. The prevalent methods tackling this problem use differential privacy or anonymization and obfuscation techniques to protect the privacy of individuals. In both cases, the utility of the trained model is sacrificed heavily in this process. In this work, we propose an effective approach called masked differential privacy (MaskDP), which allows for controlling sensitive regions where differential privacy is applied, in contrast to applying DP on the entire input. Our method operates selectively on the data and allows for defining non-sensitive spatio-temporal regions without DP application or combining differential privacy with other privacy techniques within data samples. Experiments on four challenging action recognition datasets demonstrate that our proposed techniques result in better utility-privacy trade-offs compared to standard differentially private training in the especially demanding ε<1 regime.
@inproceedings{Schneider2024maskdp, title = {Masked Differential Privacy}, author = {Schneider, David and Sajadmanesh, Sina and Sehwag, Vikash and Sarfraz, Saquib and Stiefelhagen, Rainer and Lyu, Lingjuan and Sharma, Vivek}, booktitle = {Presented at the 2nd International Workshop on Privacy-Preserving Computer Vision, ECCV}, year = {2024}, dimensions = {false} } - ICRA
 SynthAct: Towards Generalizable Human Action Recognition based on Synthetic DataDavid Schneider, Marco Keller, Zeyun Zhong, Kunyu Peng, Alina Roitberg, Jürgen Beyerer, and Rainer StiefelhagenIn 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024
SynthAct: Towards Generalizable Human Action Recognition based on Synthetic DataDavid Schneider, Marco Keller, Zeyun Zhong, Kunyu Peng, Alina Roitberg, Jürgen Beyerer, and Rainer StiefelhagenIn 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024Synthetic data generation is a proven method for augmenting training sets without the need for extensive setups, yet its application in human activity recognition is underexplored. This is particularly crucial for human-robot collaboration in household settings, where data collection is often privacy-sensitive. In this paper, we introduce SynthAct, a synthetic data generation pipeline designed to significantly minimize the reliance on real-world data. Leveraging modern 3D pose estimation techniques, SynthAct can be applied to arbitrary 2D or 3D video action recordings, making it applicable for uncontrolled in-the-field recordings by robotic agents or smarthome monitoring systems. We present two SynthAct datasets: AMARV, a large synthetic collection with over 800k multi-view action clips, and Synthetic Smarthome, mirroring the Toyota Smarthome dataset. SynthAct generates a rich set of data, including RGB videos and depth maps from four synchronized views, 3D body poses, normal maps, segmentation masks and bounding boxes. We validate the efficacy of our datasets through extensive synthetic-to-real experiments on NTU RGB+D and Toyota Smarthome. SynthAct is available on our project page.
@inproceedings{Schneider2024synthact, title = {SynthAct: Towards Generalizable Human Action Recognition based on Synthetic Data}, author = {Schneider, David and Keller, Marco and Zhong, Zeyun and Peng, Kunyu and Roitberg, Alina and Beyerer, J{\"u}rgen and Stiefelhagen, Rainer}, booktitle = {2024 IEEE International Conference on Robotics and Automation (ICRA)}, pages = {13038--13045}, year = {2024}, organization = {IEEE}, doi = {10.1109/icra57147.2024.10611486}, dimensions = {true} } - ACM-MM
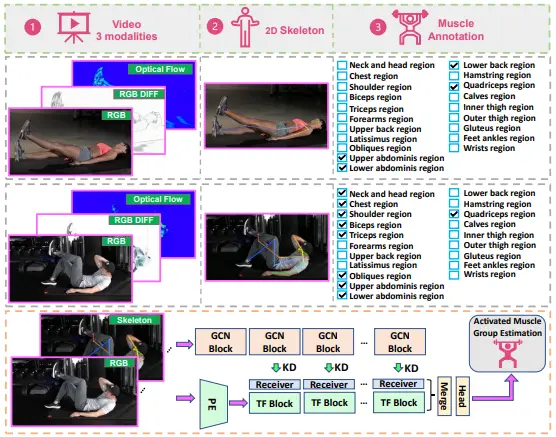 Towards Video-based Activated Muscle Group Estimation in the WildKunyu Peng, David Schneider, Alina Roitberg, Kailun Yang, Jiaming Zhang, Chen Deng , Kaiyu Zhang, M Saquib Sarfraz, and Rainer StiefelhagenIn ACM Multimedia 2024, 2024
Towards Video-based Activated Muscle Group Estimation in the WildKunyu Peng, David Schneider, Alina Roitberg, Kailun Yang, Jiaming Zhang, Chen Deng , Kaiyu Zhang, M Saquib Sarfraz, and Rainer StiefelhagenIn ACM Multimedia 2024, 2024In this paper, we tackle the new task of video-based Activated Muscle Group Estimation (AMGE) aiming at identifying active muscle regions during physical activity in the wild. To this intent, we provide the MuscleMap dataset featuring >15K video clips with 135 different activities and 20 labeled muscle groups. This dataset opens the vistas to multiple video-based applications in sports and rehabilitation medicine under flexible environment constraints. The proposed MuscleMap dataset is constructed with YouTube videos, specifically targeting High-Intensity Interval Training (HIIT) physical exercise in the wild. To make the AMGE model applicable in real-life situations, it is crucial to ensure that the model can generalize well to numerous types of physical activities not present during training and involving new combinations of activated muscles. To achieve this, our benchmark also covers an evaluation setting where the model is exposed to activity types excluded from the training set. Our experiments reveal that the generalizability of existing architectures adapted for the AMGE task remains a challenge. Therefore, we also propose a new approach, TransM3E, which employs a multi-modality feature fusion mechanism between both the video transformer model and the skeleton-based graph convolution model with novel cross-modal knowledge distillation executed on multi-classification tokens. The proposed method surpasses all popular video classification models when dealing with both, previously seen and new types of physical activities.
@inproceedings{Peng2024towards, title = {Towards Video-based Activated Muscle Group Estimation in the Wild}, author = {Peng, Kunyu and Schneider, David and Roitberg, Alina and Yang, Kailun and Zhang, Jiaming and Deng, Chen and Zhang, Kaiyu and Sarfraz, M Saquib and Stiefelhagen, Rainer}, booktitle = {ACM Multimedia 2024}, year = {2024}, dimensions = {true} } - AAAI
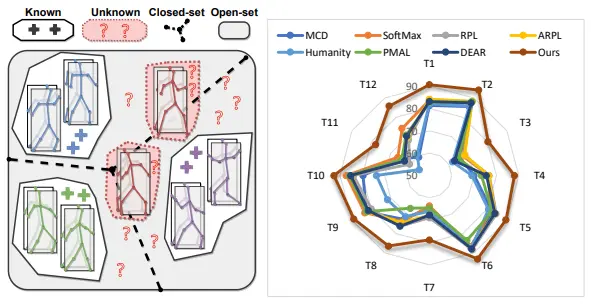 Navigating open set scenarios for skeleton-based action recognitionKunyu Peng, Cheng Yin, Junwei Zheng, Ruiping Liu, David Schneider, Jiaming Zhang, Kailun Yang, M Saquib Sarfraz, Rainer Stiefelhagen, and Alina RoitbergIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Navigating open set scenarios for skeleton-based action recognitionKunyu Peng, Cheng Yin, Junwei Zheng, Ruiping Liu, David Schneider, Jiaming Zhang, Kailun Yang, M Saquib Sarfraz, Rainer Stiefelhagen, and Alina RoitbergIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024In real-world scenarios, human actions often fall outside the distribution of training data, making it crucial for models to recognize known actions and reject unknown ones. However, using pure skeleton data in such open-set conditions poses challenges due to the lack of visual background cues and the distinct sparse structure of body pose sequences. In this paper, we tackle the unexplored Open-Set Skeleton-based Action Recognition (OS-SAR) task and formalize the benchmark on three skeleton-based datasets. We assess the performance of seven established open-set approaches on our task and identify their limits and critical generalization issues when dealing with skeleton information. To address these challenges, we propose a distance-based cross-modality ensemble method that leverages the cross-modal alignment of skeleton joints, bones, and velocities to achieve superior open-set recognition performance. We refer to the key idea as CrossMax - an approach that utilizes a novel cross-modality mean max discrepancy suppression mechanism to align latent spaces during training and a cross-modality distance-based logits refinement method during testing. CrossMax outperforms existing approaches and consistently yields state-of-the-art results across all datasets and backbones. The benchmark, code, and models will be released.
@inproceedings{Peng2024navigating, title = {Navigating open set scenarios for skeleton-based action recognition}, author = {Peng, Kunyu and Yin, Cheng and Zheng, Junwei and Liu, Ruiping and Schneider, David and Zhang, Jiaming and Yang, Kailun and Sarfraz, M Saquib and Stiefelhagen, Rainer and Roitberg, Alina}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {38}, number = {5}, pages = {4487--4496}, year = {2024}, doi = {10.1609/aaai.v38i5.28247}, dimensions = {true} }
2023
- arXiv
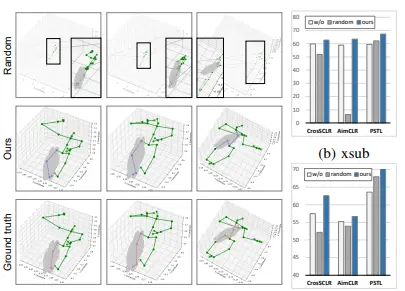 Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occluded EnvironmentsYifei Chen, Kunyu Peng, Alina Roitberg, David Schneider, Jiaming Zhang, Junwei Zheng, Ruiping Liu, Yufan Chen, Kailun Yang, and Rainer StiefelhagenarXiv preprint arXiv:2309.12029, 2023
Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occluded EnvironmentsYifei Chen, Kunyu Peng, Alina Roitberg, David Schneider, Jiaming Zhang, Junwei Zheng, Ruiping Liu, Yufan Chen, Kailun Yang, and Rainer StiefelhagenarXiv preprint arXiv:2309.12029, 2023To integrate action recognition methods into autonomous robotic systems, it is crucial to consider adverse situations involving target occlusions. Such a scenario, despite its practical relevance, is rarely addressed in existing self-supervised skeleton-based action recognition methods. To empower robots with the capacity to address occlusion, we propose a simple and effective method. We first pre-train using occluded skeleton sequences, then use k-means clustering (KMeans) on sequence embeddings to group semantically similar samples. Next, we employ K-nearest-neighbor (KNN) to fill in missing skeleton data based on the closest sample neighbors. Imputing incomplete skeleton sequences to create relatively complete sequences as input provides significant benefits to existing skeleton-based self-supervised models. Meanwhile, building on the state-of-the-art Partial Spatio-Temporal Learning (PSTL), we introduce an Occluded Partial Spatio-Temporal Learning (OPSTL) framework. This enhancement utilizes Adaptive Spatial Masking (ASM) for better use of high-quality, intact skeletons. The effectiveness of our imputation methods is verified on the challenging occluded versions of the NTURGB+D 60 and NTURGB+D 120. The source code will be made publicly available.
@article{Chen2023unveiling, title = {Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occluded Environments}, author = {Chen, Yifei and Peng, Kunyu and Roitberg, Alina and Schneider, David and Zhang, Jiaming and Zheng, Junwei and Liu, Ruiping and Chen, Yufan and Yang, Kailun and Stiefelhagen, Rainer}, journal = {arXiv preprint arXiv:2309.12029}, year = {2023}, dimensions = {true} } - arXiv
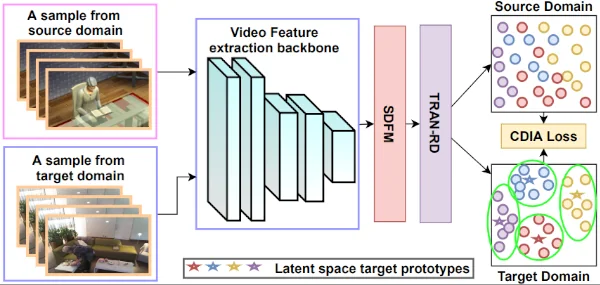 Exploring Few-Shot Adaptation for Activity Recognition on Diverse DomainsKunyu Peng, Di Wen, David Schneider, Jiaming Zhang, Kailun Yang, M Saquib Sarfraz, Rainer Stiefelhagen, and Alina RoitbergarXiv preprint arXiv:2305.08420, 2023
Exploring Few-Shot Adaptation for Activity Recognition on Diverse DomainsKunyu Peng, Di Wen, David Schneider, Jiaming Zhang, Kailun Yang, M Saquib Sarfraz, Rainer Stiefelhagen, and Alina RoitbergarXiv preprint arXiv:2305.08420, 2023Domain adaptation is essential for activity recognition to ensure accurate and robust performance across diverse environments, sensor types, and data sources. Unsupervised domain adaptation methods have been extensively studied, yet, they require large-scale unlabeled data from the target domain. In this work, we focus on Few-Shot Domain Adaptation for Activity Recognition (FSDA-AR), which leverages a very small amount of labeled target videos to achieve effective adaptation. This approach is appealing for applications because it only needs a few or even one labeled example per class in the target domain, ideal for recognizing rare but critical activities. However, the existing FSDA-AR works mostly focus on the domain adaptation on sports videos, where the domain diversity is limited. We propose a new FSDA-AR benchmark using five established datasets considering the adaptation on more diverse and challenging domains. Our results demonstrate that FSDA-AR performs comparably to unsupervised domain adaptation with significantly fewer labeled target domain samples. We further propose a novel approach, RelaMiX, to better leverage the few labeled target domain samples as knowledge guidance. RelaMiX encompasses a temporal relational attention network with relation dropout, alongside a cross-domain information alignment mechanism. Furthermore, it integrates a mechanism for mixing features within a latent space by using the few-shot target domain samples. The proposed RelaMiX solution achieves state-of-the-art performance on all datasets within the FSDA-AR benchmark. To encourage future research of few-shot domain adaptation for activity recognition, our code will be publicly available.
@article{Peng2023exploring, title = {Exploring Few-Shot Adaptation for Activity Recognition on Diverse Domains}, author = {Peng, Kunyu and Wen, Di and Schneider, David and Zhang, Jiaming and Yang, Kailun and Sarfraz, M Saquib and Stiefelhagen, Rainer and Roitberg, Alina}, journal = {arXiv preprint arXiv:2305.08420}, year = {2023}, dimensions = {true} } - WACV
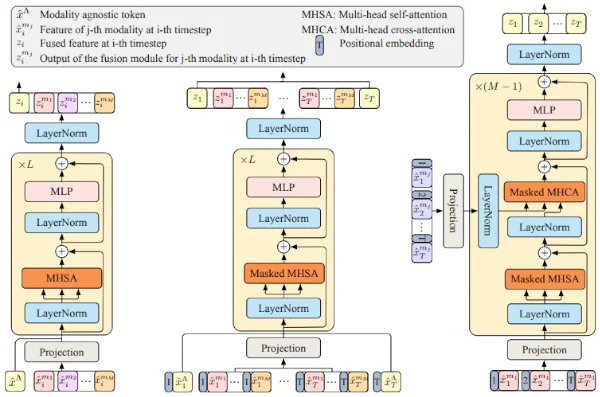 Anticipative feature fusion transformer for multi-modal action anticipationZeyun* Zhong, David* Schneider, Michael Voit, Rainer Stiefelhagen, and Jürgen BeyererIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023
Anticipative feature fusion transformer for multi-modal action anticipationZeyun* Zhong, David* Schneider, Michael Voit, Rainer Stiefelhagen, and Jürgen BeyererIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023Although human action anticipation is a task which is inherently multi-modal, state-of-the-art methods on well known action anticipation datasets leverage this data by applying ensemble methods and averaging scores of unimodal anticipation networks. In this work we introduce transformer based modality fusion techniques, which unify multi-modal data at an early stage. Our Anticipative Feature Fusion Transformer (AFFT) proves to be superior to popular score fusion approaches and presents state-of-the-art results outperforming previous methods on EpicKitchens-100 and EGTEA Gaze+. Our model is easily extensible and allows for adding new modalities without architectural changes. Consequently, we extracted audio features on EpicKitchens-100 which we add to the set of commonly used features in the community.
@inproceedings{Zhong2023anticipative, title = {Anticipative feature fusion transformer for multi-modal action anticipation}, author = {Zhong, Zeyun and Schneider, David and Voit, Michael and Stiefelhagen, Rainer and Beyerer, J{\"u}rgen}, booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, pages = {6068--6077}, year = {2023}, dimensions = {true}, doi = {10.1109/wacv56688.2023.00601} }
2022
- ECCV
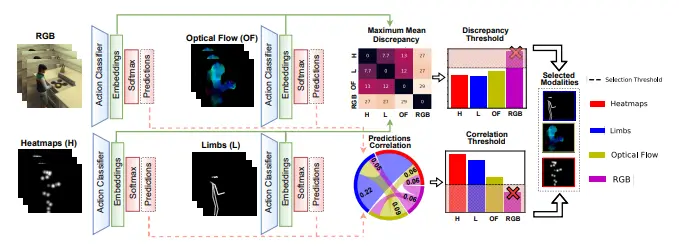 Modselect: Automatic modality selection for synthetic-to-real domain generalizationIn European Conference on Computer Vision, 2022
Modselect: Automatic modality selection for synthetic-to-real domain generalizationIn European Conference on Computer Vision, 2022Modality selection is an important step when designing multimodal systems, especially in the case of cross-domain activity recognition as certain modalities are more robust to domain shift than others. However, selecting only the modalities which have a positive contribution requires a systematic approach. We tackle this problem by proposing an unsupervised modality selection method (ModSelect), which does not require any ground-truth labels. We determine the correlation between the predictions of multiple unimodal classifiers and the domain discrepancy between their embeddings. Then, we systematically compute modality selection thresholds, which select only modalities with a high correlation and low domain discrepancy. We show in our experiments that our method ModSelect chooses only modalities with positive contributions and consistently improves the performance on a Synthetic-to-Real domain adaptation benchmark, narrowing the domain gap.
@inproceedings{Marinov2022modselect, title = {Modselect: Automatic modality selection for synthetic-to-real domain generalization}, author = {Marinov, Zdravko and Roitberg, Alina and Schneider, David and Stiefelhagen, Rainer}, booktitle = {European Conference on Computer Vision}, pages = {326--346}, year = {2022}, organization = {Springer}, dimensions = {true}, doi = {10.1007/978-3-031-25085-9_19} } - IROS
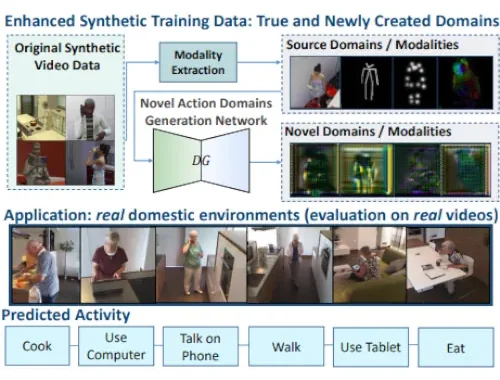 Multimodal Generation of Novel Action Appearances for Synthetic-to-Real Recognition of Activities of Daily LivingIn 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
Multimodal Generation of Novel Action Appearances for Synthetic-to-Real Recognition of Activities of Daily LivingIn 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022Domain shifts, such as appearance changes, are a key challenge in real-world applications of activity recognition models, which range from assistive robotics and smart homes to driver observation in intelligent vehicles. For example, while simulations are an excellent way of economical data collection, a Synthetic-to-Real domain shift leads to a > 60% drop in accuracy when recognizing activities of Daily Living (ADLs). We tackle this challenge and introduce an activity domain generation framework which creates novel ADL appearances (novel domains) from different existing activity modalities (source domains) inferred from video training data. Our framework computes human poses, heatmaps of body joints, and optical flow maps and uses them alongside the original RGB videos to learn the essence of source domains in order to generate completely new ADL domains. The model is optimized by maximizing the distance between the existing source appearances and the generated novel appearances while ensuring that the semantics of an activity is preserved through an additional classification loss. While source data multimodality is an important concept in this design, our setup does not rely on multi-sensor setups, (i.e., all source modalities are inferred from a single video only.) The newly created activity domains are then integrated in the training of the ADL classification networks, resulting in models far less susceptible to changes in data distributions. Extensive experiments on the Synthetic-to-Real benchmark Sims4Action demonstrate the potential of the domain generation paradigm for cross-domain ADL recognition, setting new state-of-the-art results
@inproceedings{Marinov2022multimodal, title = {Multimodal Generation of Novel Action Appearances for Synthetic-to-Real Recognition of Activities of Daily Living}, author = {Marinov, Zdravko and Schneider, David and Roitberg, Alina and Stiefelhagen, Rainer}, booktitle = {2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {11320--11327}, year = {2022}, organization = {IEEE}, dimensions = {true}, doi = {10.1109/iros47612.2022.9981946}, } - CVPRW
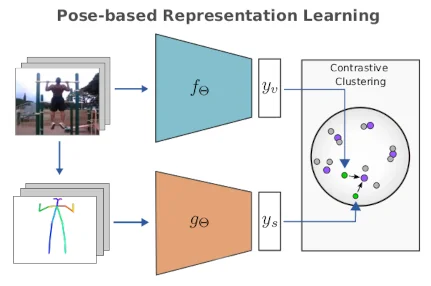 Pose-Based Contrastive Learning for Domain Agnostic Activity RepresentationsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Jun 2022
Pose-Based Contrastive Learning for Domain Agnostic Activity RepresentationsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Jun 2022While recognition accuracies of video classification models trained on conventional benchmarks are gradually saturating, recent studies raise alarm about the learned representations not generalizing well across different domains. Learning abstract concepts behind an activity instead of overfitting to the appearances and biases of a specific benchmark domain is vital for building generalizable behaviour understanding models. In this paper, we introduce Pose-based High Level View Contrasting (P-HLVC), a novel method that leverages human pose dynamics as a supervision signal aimed at learning domain-invariant activity representations. Our model learns to link image sequences to more abstract body pose information through iterative contrastive clustering and the Sinkhorn-Knopp algorithm, providing us with video representations more resistant to domain shifts. We demonstrate the effectiveness of our approach in a cross-domain action recognition setting and achieve significant improvements on the synthetic-to-real Sims4Action benchmark
@inproceedings{Schneider_2022_CVPR, author = {Schneider, David and Sarfraz, Saquib and Roitberg, Alina and Stiefelhagen, Rainer}, title = {Pose-Based Contrastive Learning for Domain Agnostic Activity Representations}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, month = jun, year = {2022}, pages = {3433-3443}, doi = {10.1109/cvprw56347.2022.00387}, dimensions = {true} } - Journal
 Erfassung und Interpretation menschlicher Handlungen für die Programmierung von Robotern in der ProduktionChristian R. G. Dreher, Manuel Zaremski, Fabian Leven, David Schneider, Alina Roitberg, Rainer Stiefelhagen, Michael Heizmann, Barbara Deml, and Tamim Asfourat - Automatisierungstechnik, Jun 2022
Erfassung und Interpretation menschlicher Handlungen für die Programmierung von Robotern in der ProduktionChristian R. G. Dreher, Manuel Zaremski, Fabian Leven, David Schneider, Alina Roitberg, Rainer Stiefelhagen, Michael Heizmann, Barbara Deml, and Tamim Asfourat - Automatisierungstechnik, Jun 2022Human workers are the most flexible, but also an expensive resource in a production system. In the context of remanufacturing, robots are a cost-effective alternative, but their programming is often not profitable and time-consuming. Programming by demonstration promises a flexible and intuitive alternative that would be feasible even for non-experts, but this first requires capturing and interpreting the human actions. This work presents a multi-sensory robot-supported platform that enables capturing bimanual manipulation actions as well as human poses, hand and gaze movements during manual disassembly tasks. As part of a study, subjects were recorded on this platform during the disassembly of electric motors in order to obtain adequate datasets for the recognition and classification of human actions.
@article{DreherZaremskiLevenSchneiderRoitbergStiefelhagenHeizmannDemlAsfour+2022+517+533, author = {Dreher, Christian R. G. and Zaremski, Manuel and Leven, Fabian and Schneider, David and Roitberg, Alina and Stiefelhagen, Rainer and Heizmann, Michael and Deml, Barbara and Asfour, Tamim}, doi = {doi:10.1515/auto-2022-0006}, url = {https://doi.org/10.1515/auto-2022-0006}, title = {Erfassung und Interpretation menschlicher Handlungen für die Programmierung von Robotern in der Produktion}, journal = {at - Automatisierungstechnik}, number = {6}, volume = {70}, year = {2022}, pages = {517--533}, lastchecked = {2022-07-04}, dimensions = {false} } - T-ITS
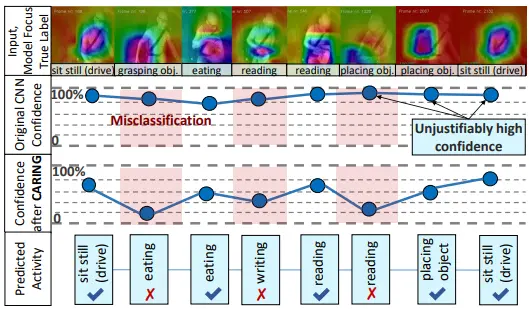 Is My Driver Observation Model Overconfident? Input-Guided Calibration Networks for Reliable and Interpretable Confidence EstimatesAlina Roitberg, Kunyu Peng, David Schneider, Kailun Yang, Marios Koulakis, Manuel Martinez, and Rainer StiefelhagenIEEE Transactions on Intelligent Transportation Systems, Jun 2022
Is My Driver Observation Model Overconfident? Input-Guided Calibration Networks for Reliable and Interpretable Confidence EstimatesAlina Roitberg, Kunyu Peng, David Schneider, Kailun Yang, Marios Koulakis, Manuel Martinez, and Rainer StiefelhagenIEEE Transactions on Intelligent Transportation Systems, Jun 2022Driver observation models are rarely deployed under perfect conditions. In practice, illumination, camera placement and type differ from the ones present during training and unforeseen behaviours may occur at any time. While observing the human behind the steering wheel leads to more intuitive human-vehicle-interaction and safer driving, it requires recognition algorithms which do not only predict the correct driver state, but also determine their prediction quality through realistic and interpretable confidence measures. Reliable uncertainty estimates are crucial for building trust and are a serious obstacle for deploying activity recognition networks in real driving systems. In this work, we for the first time examine how well the confidence values of modern driver observation models indeed match the probability of the correct outcome and show that raw neural network-based approaches tend to significantly overestimate their prediction quality. To correct this misalignment between the confidence values and the actual uncertainty, we consider two strategies. First, we enhance two activity recognition models often used for driver observation with temperature scaling-an off-the-shelf method for confidence calibration in image classification. Then, we introduce Calibrated Action Recognition with Input Guidance (CARING)-a novel approach leveraging an additional neural network to learn scaling the confidences depending on the video representation. Extensive experiments on the Drive&Act dataset demonstrate that both strategies drastically improve the quality of model confidences, while our CARING model out-performs both, the original architectures and their temperature scaling enhancement, leading to best uncertainty estimates.
@article{Roitberg2022my, author = {Roitberg, Alina and Peng, Kunyu and Schneider, David and Yang, Kailun and Koulakis, Marios and Martinez, Manuel and Stiefelhagen, Rainer}, journal = {IEEE Transactions on Intelligent Transportation Systems}, title = {Is My Driver Observation Model Overconfident? Input-Guided Calibration Networks for Reliable and Interpretable Confidence Estimates}, year = {2022}, volume = {23}, number = {12}, pages = {25271-25286}, keywords = {Vehicles;Activity recognition;Uncertainty;Reliability;Neural networks;Predictive models;Calibration;Driver activity recognition;model confidence reliability;uncertainty in deep learning}, doi = {10.1109/TITS.2022.3196410}, dimensions = {true} } - IV
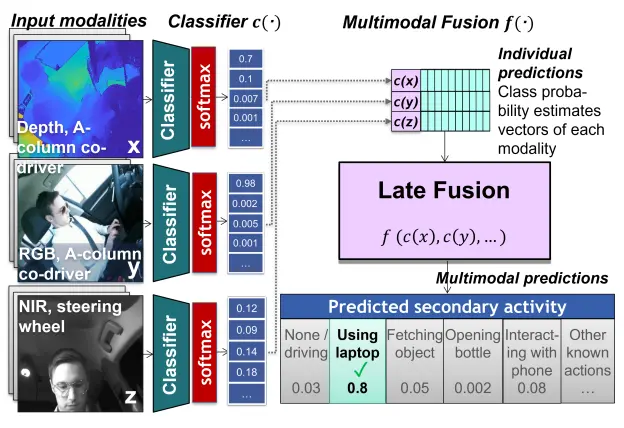 A Comparative Analysis of Decision-Level Fusion for Multimodal Driver Behaviour UnderstandingAlina Roitberg, Kunyu Peng, Zdravko Marinov, Constantin Seibold, David Schneider, and Rainer StiefelhagenIn Intelligent Vehicles Symposium 2022, IEEE, Jun 2022
A Comparative Analysis of Decision-Level Fusion for Multimodal Driver Behaviour UnderstandingAlina Roitberg, Kunyu Peng, Zdravko Marinov, Constantin Seibold, David Schneider, and Rainer StiefelhagenIn Intelligent Vehicles Symposium 2022, IEEE, Jun 2022Visual recognition inside the vehicle cabin leads to safer driving and more intuitive human-vehicle interaction but such systems face substantial obstacles as they need to capture different granularities of driver behaviour while dealing with highly limited body visibility and changing illumination. Multimodal recognition mitigates a number of such issues: prediction outcomes of different sensors complement each other due to different modality-specific strengths and weaknesses. While several late fusion methods have been considered in previously published frameworks, they constantly feature different architecture backbones and building blocks making it very hard to isolate the role of the chosen late fusion strategy itself. This paper presents an empirical evaluation of different paradigms for decision-level late fusion in video-based driver observation. We compare seven different mechanisms for joining the results of single-modal classifiers which have been both popular, (e.g. score averaging) and not yet considered (e.g. rank-level fusion) in the context of driver observation evaluating them based on different criteria and benchmark settings. This is the first systematic study of strategies for fusing outcomes of multimodal predictors inside the vehicles, conducted with the goal to provide guidance for fusion scheme selection.
@inproceedings{https://doi.org/10.48550/arxiv.2204.04734, doi = {10.48550/ARXIV.2204.04734}, url = {https://arxiv.org/abs/2204.04734}, author = {Roitberg, Alina and Peng, Kunyu and Marinov, Zdravko and Seibold, Constantin and Schneider, David and Stiefelhagen, Rainer}, title = {A Comparative Analysis of Decision-Level Fusion for Multimodal Driver Behaviour Understanding}, booktitle = {Intelligent Vehicles Symposium 2022, IEEE}, year = {2022}, dimensions = {true} }
2021
- FG
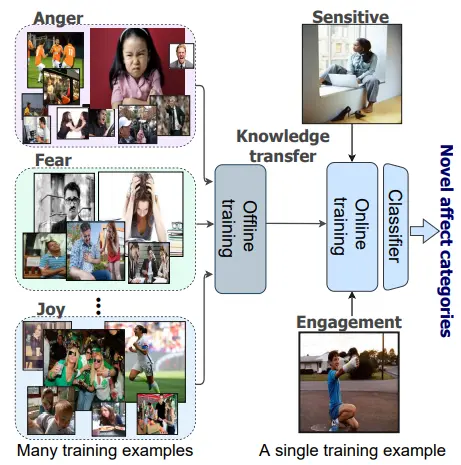 Affect-DML: Context-Aware One-Shot Recognition of Human Affect using Deep Metric LearningIn 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jun 2021
Affect-DML: Context-Aware One-Shot Recognition of Human Affect using Deep Metric LearningIn 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jun 2021Human affect recognition is a well-established research area with numerous applications, e.g., in psychological care, but existing methods assume that all emotions-of-interest are given a priori as annotated training examples. However, the rising granularity and refinements of the human emotional spectrum through novel psychological theories and the increased consideration of emotions in context brings considerable pressure to data collection and labeling work. In this paper, we conceptualize one-shot recognition of emotions in context – a new problem aimed at recognizing human affect states in finer particle level from a single support sample. To address this challenging task, we follow the deep metric learning paradigm and introduce a multi-modal emotion embedding approach which minimizes the distance of the same-emotion embeddings by leveraging complementary information of human appearance and the semantic scene context obtained through a semantic segmentation network. All streams of our context-aware model are optimized jointly using weighted triplet loss and weighted cross entropy loss. We conduct thorough experiments on both, categorical and numerical emotion recognition tasks of the Emotic dataset adapted to our one-shot recognition problem, revealing that categorizing human affect from a single example is a hard task. Still, all variants of our model clearly outperform the random baseline, while leveraging the semantic scene context consistently improves the learnt representations, setting state-of-the-art results in one-shot emotion recognition. To foster research of more universal representations of human affect states, we will make our benchmark and models publicly available to the community.
@inproceedings{Peng2021affect, title = {Affect-DML: Context-Aware One-Shot Recognition of Human Affect using Deep Metric Learning}, author = {Peng, Kunyu and Roitberg, Alina and Schneider, David and Koulakis, Marios and Yang, Kailun and Stiefelhagen, Rainer}, booktitle = {2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021)}, pages = {1--8}, year = {2021}, organization = {IEEE}, doi = {10.1109/fg52635.2021.9666940}, dimensions = {true} } - IROS
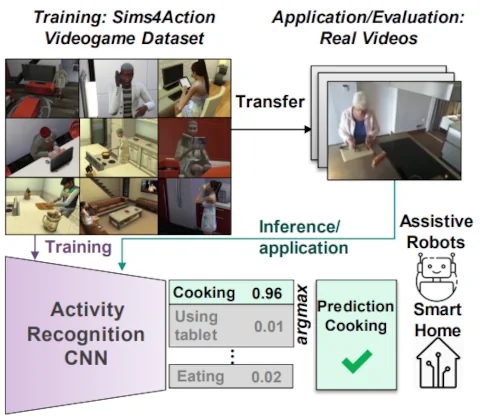 Let’s Play for Action: Recognizing Activities of Daily Living by Learning from Life Simulation Video GamesAlina* Roitberg, David* Schneider, Aulia Djamal, Constantin Seibold, Simon Reiß, and Rainer StiefelhagenIn 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2021
Let’s Play for Action: Recognizing Activities of Daily Living by Learning from Life Simulation Video GamesAlina* Roitberg, David* Schneider, Aulia Djamal, Constantin Seibold, Simon Reiß, and Rainer StiefelhagenIn 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2021Recognizing Activities of Daily Living (ADL) is a vital process for intelligent assistive robots, but collecting large annotated datasets requires time-consuming temporal labeling and raises privacy concerns, e.g., if the data is collected in a real household. In this work, we explore the concept of constructing training examples for ADL recognition by playing life simulation video games and introduce the SIMS4ACTION dataset created with the popular commercial game THE SIMS 4. We build Sims4Action by specifically executing actions-of-interest in a "top-down" manner, while the gaming circumstances allow us to freely switch between environments, camera angles and subject appearances. While ADL recognition on gaming data is interesting from the theoretical perspective, the key challenge arises from transferring it to the real-world applications, such as smart-homes or assistive robotics. To meet this requirement, Sims4Action is accompanied with a GamingToReal benchmark, where the models are evaluated on real videos derived from an existing ADL dataset. We integrate two modern algorithms for video-based activity recognition in our framework, revealing the value of life simulation video games as an inexpensive and far less intrusive source of training data. However, our results also indicate that tasks involving a mixture of gaming and real data are challenging, opening a new research direction.
@inproceedings{RoitbergSchneider2021Sims4ADL, author = {Roitberg, Alina and Schneider, David and Djamal, Aulia and Seibold, Constantin and Reiß, Simon and Stiefelhagen, Rainer}, title = {Let's Play for Action: Recognizing Activities of Daily Living by Learning from Life Simulation Video Games}, booktitle = {2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2021}, organization = {IEEE}, doi = {10.1109/IROS51168.2021.9636381}, dimensions = {true} }
2019
- IROS
 An Interactive Indoor Drone AssistantT. Fuhrman, D. Schneider, F. Altenberg, T. Nguyen, S. Blasen, S. Constantin, and A. WaibelIn 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2019
An Interactive Indoor Drone AssistantT. Fuhrman, D. Schneider, F. Altenberg, T. Nguyen, S. Blasen, S. Constantin, and A. WaibelIn 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Jun 2019With the rapid advance of sophisticated control algorithms, the capabilities of drones to stabilise, fly and manoeuvre autonomously have dramatically improved, enabling us to pay greater attention to entire missions and the interaction of a drone with humans and with its environment during the course of such a mission. In this paper, we present an indoor office drone assistant that is tasked to run errands and carry out simple tasks at our laboratory, while given instructions from and interacting with humans in the space. To accomplish its mission, the system has to be able to understand verbal instructions from humans, and perform subject to constraints from control and hardware limitations, uncertain localisation information, unpredictable and uncertain obstacles and environmental factors. We combine and evaluate the dialogue, navigation, flight control, depth perception and collision avoidance components. We discuss performance and limitations of our assistant at the component as well as the mission level. A 78% mission success rate was obtained over the course of 27 missions.
@inproceedings{FuhrmanSchneiderAltenberg2019_1000118474, author = {Fuhrman, T. and Schneider, D. and Altenberg, F. and Nguyen, T. and Blasen, S. and Constantin, S. and Waibel, A.}, year = {2019}, title = {An Interactive Indoor Drone Assistant}, pages = {6052-6057}, eventtitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems}, eventtitleaddon = {IROS 2019}, eventdate = {2019-11-03/2019-11-08}, venue = {Macao, Macao}, booktitle = {2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, doi = {10.1109/IROS40897.2019.8967587}, publisher = {{Institute of Electrical and Electronics Engineers (IEEE)}}, isbn = {978-1-72814-004-9}, issn = {2153-0858}, language = {english}, dimensions = {true} }